En esta segunda entrada vamos hablar lo ultimo de la teoria!, aunque faltan algunas cosas mas por ver, espero que le sirva, para los que se perdieron el primer articulo, se los dejo aqui:
Registros
Los procesadores de la arquitectura x86 disponen de un banco de registros, los cuales son utilizados para las diferentes operaciones realizadas por la Unidad Central de procesamiento (CPU), existen registros de propósito general y registros de propósito específicos. Por ahora nos centraremos en los registros de propósito general, como se puede observar en la siguiente imagen:
 |
| Registros de propósito general |
 |
| Registros - Immunity Debugger |
Puntero a la siguiente instrucción, registro solo lectura (Este es con el vamos a interactuar mas).
Aplicación en memoria
Cuando una aplicación es ejecutada, el propio ejecutable y todas sus librerías (DLL) son cargadas en la memoria. Cada aplicación tiene asignada tiene 4GB (32 bit, hagan cálculos ;)) de memoria virtual, cuando la aplicación es ejecutada el “gestor de memoria” automáticamente mapea direcciones de memoria virtual en direcciones de la memoria física. La gestión de la memoria es responsabilidad directamente del sistema operativo.
La memoria es dividida entre “User
mode” y “kernel mode”. “User mode” es el área de memoria donde una aplicación
es cargada y ejecutada en memoria, por otro lado el “kernel mode” es la región
donde los componentes del kernel son cargados y ejecutados, siguiendo este
modelo, una aplicación no podría directamente acceder a un región de memoria
perteneciente al “Kernel mode”.
 |
| Aplicación en Memoria - Visión General |
Endianess
Es la forma de representar la información mayor a 1 byte, “Little Endian” significa que el byte de menor peso se almacena en la dirección más baja de la memoria y el byte de mayor peso en la más alta.
 |
| Formato Little Endian |
Por otro lado en “Big Endian” el
byte de mayor peso se almacena en la dirección más baja de memoria y el byte de
menor peso en la dirección más alta.
 |
| Formato Big Endian |
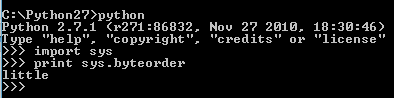 |
| Python |
Cada aplicación es cargada en 3
diferentes áreas de memoria: Segmento Stack
(Pila), segmento Data (Datos) y el segmento (Code, Text), El
segmento de la pila almacena variables locales y llamadas a procedimientos, el
segmento de datos almacena variables estáticas y dinámicas, el segmento de
texto almacena las instrucciones del programa.
El segmento de la pila y datos
son privados para cada una de las aplicaciones, es decir entre diferentes
aplicaciones no pueden acceder a estos segmentos, el segmento de texto es solo
de lectura y puede ser accedido por diferentes aplicaciones.
 |
| Mapa de Memoria Windows |
Asignación de memoria: (Pila / Stack)
La pila (Stack) es un área reservada en memoria virtual usada por la aplicación, la pila trabaja con una estructura (LIFO, Last In First Out), las operaciones más comunes son Pop (sacar) y push (agregar) datos a la pila.
Cuando se hace push sobre la pila la cima actual de la
pila (ESP) decrementa 4 bytes antes del recientemente ítem agregado. En tal
sentido cuando se hace un Pop de un ítem se incrementa 4 bytes.
Un “Stack Frame” es una estructura de datos creada durante la llamada a
una función, el objetivo es de mantener los parámetros de la función principal
y pasar argumentos a la función.
Se puede acceder a la ubicación actual
del puntero de la pila, accediendo ESP (apuntador de la pila), se puede acceder
a la base actual de la pila utilizando el registro (EBP), de igual forma se
puede acceder a la ejecución (actual) accediendo al registro EIP.
 |
| Asignacion de memoria |
Saludos!
Desarrollo de Exploit Win32 : Registros, Memory layout,Stack, Endianess
By Israel Araoz

No llevo mucho tiempo en el mundo
del Exploiting pero quiero compartir con ustedes lo que he aprendido en cursos,
libros y recursos en la web, además de practicar es necesario llenarse de
paciencia.
Con esta entrada daré inicio a
una serie de artículos relacionados al mundo del Exploiting, si crees que algo
de lo que escribe esta errado, ¡por favor deja un comentario!
Proceso de desarrollo de un Exploit
Es muy importante seguir las
fases en un orden lógico y establecido, esto garantizará que nuestro exploit funcione
de manera correcta o en todo caso evitar invertir tiempo innecesario en el
desarrollo de exploit. No importa las herramientas, solo la metodología.
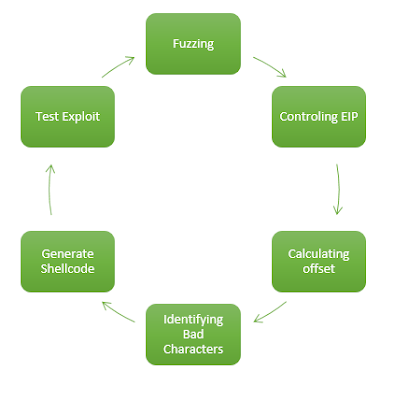 |
| Proceso de desarollo de exploit |
Fuzzing
Esta fase es muy importante, aquí
es donde inicia todo el proceso, en esta fase generamos información de manera
aleatoria que posteriormente es enviada por diferentes medios (Protocolos de
red, Archivos mal formados, de forma local) a la aplicación en cuestión para
ver cómo reacciona a datos no esperados.
Controling EIP
Una vez identificada o desencadena
la vulnerabilidad es momento de conseguir escribir la dirección de memoria que
esta almacenada en el registro EIP (Registro solo lectura, ¡no sobre-escribimos
EIP!, ¡por favor!) muchas veces y dependiendo de la técnica o método de
explotación lo conseguiremos, más allá de solo trabajar con el registro EIP, en
esta fase debemos controlar el flujo de ejecución de la aplicación vulnerable.
Existen dos formas de realizar esto, una atravesó de un análisis binario y la
otra y más conocida es enviando una cadena única de caracteres, esta última será
la que utilizaremos.
Calculating offset
Una vez controlado el flujo de ejecución
de la aplicación vulnerable, necesitamos calcular la cantidad de datos que
debemos de generar mediante una cadena única de caracteres para determinar el
espacio que tenemos para nuestro payload, por lo general un reverse Shell payload
estándar debería estar entre los 300 a 400 bytes, con esto verifica la
disponibilidad de espacio para nuestro payload
Identifying bad Characters
Dependiendo de la aplicación y /o
la vulnerabilidad existen caracteres especiales que pueden llegar a interrumpir
la ejecución de la aplicación vulnerable, los cuales no deberían encontrarse en
direcciones de memoria o nuestra Shellcode.
Generate Shellcode
Aquí es donde generamos nuestra Shellcode,
por lo general utlizamos herramientas de terceros para evitar como msfvenom (https://github.com/rapid7/metasploit-framework/wiki/How-to-use-msfvenom)
, existen diferentes métodos y formas de codificar nuestra Shellcode para no
ser detectada por los AV.
Test exploit!
Esta fase es donde ejecutamos
nuestro exploit construido, seguramente con un sistema operativo “Vainilla”
funcionará perfectamente, en un mundo real debemos evadir diferentes contramedidas implementadas
a nivel de Sistema Operativo o las que son agregadas en tiempo de compilación de
la aplicación vulnerable, alguna de ellas son ASLR,DEP, StackCookie, SafeSEH, SeHOP.
Por cada fase identificada escribiere una entrada
en mi blog, hasta llegar a la creación de un exploit paso a paso.
Si tenes alguna duda podes mandarme un DM via twitter y con gusto te ayudo con lo que pueda @yaritu_
Saludos!
Desarrollo de Exploit Win32 : Proceso de Desarollo de un Exploit
By Israel Araoz
Suscribirse a:
Entradas (Atom)


